


图片来源@视觉中国
文 | 半导体产业纵横
处理器芯片经历了从专用到通用,再从通用到专用的两次转变。Henessy和Patterson提出了特定领域架构(DSA)的概念,以冯·诺依曼体系的诞生作为分界线,在此之前晶体管计算机、录音机、计算器等使用不同的芯片,而在冯·诺依曼体系诞生后,芯片逐渐走向通用CPU。
领域特定架构
随着摩尔定律的减速,通用CPU对于图形处理计算的速度较慢,也因此GPU诞生,解放了原本CPU的部分工作。Henessy和Patterson提出的特定领域架构(DSA)的概念,而GPU就是用于3D图形领域的DSA。
下图对CPU和GPU的逻辑架构进行了对比。其中Control是控制单元,ALU是逻辑运算单元,Cache是其内部缓存,DRAM就是内存。可以看到,CPU虽然也是多核,但总数没有超过两位数,且需要复杂的控制单元和缓存。
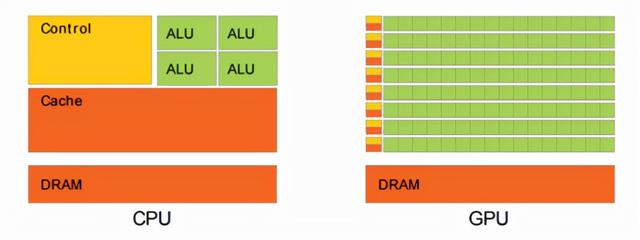
而GPU的优势在于多核,其核数远超CPU可以达到数百个,每个核拥有的缓存相对较小,数字逻辑运算单元少且简单。从实际来看,CPU芯片空间的5%是ALU,而GPU空间的40%是ALU,这也成为GPU计算能力超强的原因。
正因为GPU的原理,今天的GPU不仅具备高质量和高性能图形处理能力,还可以用于通用计算。事实证明,在浮点运算、并行运算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能,GPU使得显卡减少了对于CPU的依赖,并进行部分原本CPU的工作。
因此,GPU具有双重属性:一是图像处理,另一个是高速计算。
GPU未来发展趋势
作为创造出GPU的公司,英伟达对于GPU的定位和探索对于窥探行业未来发展非常重要。GPU未来如何发展,从历年英伟达举办的中国GTC大会中可见一二。在2019年中国GTC大会上英伟达设置了两大主题,分别是AI和图形。在2020年,GTC大会的主题分论坛则包含深度学习、自主机器和边缘计算、高性能计算与专业图形等。
")
来源:英伟达官网
不难看出,GPU未来徘徊于其双重属性AI DSA和3D DSA之间,并且人工智能计算、大规模扩展计算能力的高性能计算、专业图像显示是目前GPU的主要发展方向。
尽管GPU具有双重属性,但这两重属性是无法同时得到拓展的。AI DSA需要加速张量运算,这是一种在AI中很常见的运算,但是在3D视觉中是没有的,同时,为3D用途准备的固定功能硬件对于AI来说一般是不需要的。
在论文《GPU Domain Specialization via Composable On-Package Architecture Share on》中,也展示了GPU中高精度与低精度数学运算吞吐量强烈的差异。这个鸿沟导致设计一个能够同时支持高性能计算和深度学习使用的存储系统是非常困难的。
因此,尽管GPU适用于多领域运用,但遗憾的是目前GPU无法同时出色实现某两个领域的极致。
1.高性能计算
高性能计算(HPC)常用于大数据分析、超级计算、高级建模和模拟,超级计算机代表着高性能计算系统最尖端的水平。
其工作原理是异构计算,通过多个计算节点利用GPU主力的并行处理能力,HPC能够高效、可靠、快速地运行先进的大型应用程序项目,速度提升后可大幅提升吞吐量并降低成本。
英伟达最新发布的Tesla V100s高性能计算GPU,其有640个Tensor内核,集成5120个CUDA Core,640个Tensor Core,采用32 GB HBM2显存,显存带宽达1134GB/S,单精度浮点计算能力达16.4 TFLOPS。
2.AI领域
由于GPU良好的矩阵计算能力和并行计算的特性,是最早被用于AI计算的,这也是为什么英伟达CEO多次表达过:“英伟达不是一家游戏公司,而是一家AI公司。”AI运算指以“深度学习”为代表的神经网络算法,需要系统高效处理大量结构化数据,例如文本、视频、图像、语言等。
自2012年以来,人工智能训练任务所需求的算力每3.43个月就会翻倍,大大超越了芯片产业长期存在的摩尔定律(每 18个月芯片的性能翻一倍)。
深度学习需要处理海量数据,并进行大量简单运算,对于并行计算有较高的要求。而GPU的优势就在于,第一核数较多,可以执行海量数据的并行计算;第二,有更高的访存速度;第三,有更高的浮点运算能力。
人工智能运行过程中有两部分:训练与推理。
")
深度学习模型的训练与推理
训练(Training)可以看作是“教育”的过程,通过大数据训练出一个复杂的神经网络模型。推理(inference)可以看作是算法应用的过程,利用训练好的模型,使用新数据推理出各种结论。
GPU是AI“训练”阶段比较合适的芯片,在云端训练芯片中占据较大份额,达到64%,2019年-2021年年复合增长率达到40%。
3.光线追踪
IDC认为,2019年第二季度全球游戏PC和游戏显示器出货量同比增长16.5%,其原因在于“支持光线追踪游戏机型的大量推出”。
光线追踪与光栅化的实现原理不同,最早由IBM于1969年在“SomeTechniques for Shading Machine Renderings of Solids”中提出,光追技术能够完美地计算光线反射、折射、散射等路线,渲染的画面较为逼真,几乎与真实世界真假莫辨。
但该技术的计算量非常大,在过去实时光线追踪技术只在影视作品中出现,并且仅限于高成本的电影制作中。
2018年NVIDIA发布的RTX 2080 GPU,采用Turing架构,在GPU中集成了 68个独立的 RT(ray tracing) Core ,用于光线追踪,光线处理能力达到了10 Giga/S,1080P@60Hz需要处理的光线约为6Giga/S,实测基于光线追踪的应用其帧率大致在50FPS左右,基于RTX 2080的光线追踪达到了可用的程度。
GPU未来何解?
前文我们曾提到过,GPU中高精度与低精度数学运算吞吐量具有很大差异。
")
图一 同时设置大批量和小批量,利用MLPerf深度学习训练和推理方法分析GPU-N的性能瓶颈
当同时设置大批量和小批量的MLPerf套件进行深度学习工作负载的模拟性能瓶颈分析,其结果如图一所示。内存带宽是深度学习的主要限制,在大批量和小批量的情况下贡献了28%的执行时间,DRAM带宽则是大批量深度学习推理的主要瓶颈,占有30%的执行时间。
")
图二 不同DRAM带宽下,高性能计算应用的性能加速,虚线代表对应配置的几何加速
再来看高性能计算,与深度学习应用相反,大多数高性能计算对于DRAM带宽的变换并不敏感,当DRAM带宽增加到无限大的时候,几何平均加速只有5%。当DRAM带宽减小时,0.75倍带宽和0.5倍带宽只让性能减小了4%和14%。
因此,GPU的内存带宽会成为限制基于GPU的深度学习训练与推理的主要瓶颈,但这一限制在高性能计算中一般不会遇到。这就意味着,如果未来面向深度学习和高性能计算领域的融合GPU仍然是实际标准的话,未来DRAM带宽的增大很大程度上不会被高性能计算的应用利用到。
COPA-GPU
英伟达提出了COPA-GPA架构,提供面向高性能计算和深度学习两类不同应用的GPU高层次设计,其特定的COPA-GPU设计,将每个GPU的训练和推理性能分别提高了31%和35%,同时显著降低了数据中心拓展GPU训练的成本。
COPA-GPU的架构领域定制通过集成GPM和专用领域优化的MSM实现,该MSM可以利用平面或垂直的裸芯堆叠方法,使用2.5D或3D封装集成。
")
图三 COPA-GPU架构的两种选择2.5D和3D集成领域(a)融合GPU,使用3D封装技术的COPA-GPU,没有L3(b)3D封装可组合GPU,有L3(c)2.5D封装可组合GPU,无L3(d)2.5D封装可组合GPU,有L3和更多的DRAM
2.5D COPA-GPU的主要缺点是增加了封装的大小,而相反的是3D COPA-GPU对于封装复杂性的影响最小,但基础GPM需要考虑到用于垂直裸片间通信但分布式裸片上超高宽链接的实现。
本文链接:https://www.zhantian9.com/228290.html
相关推荐
-
淘宝网导购(淘宝网导购平台)
编辑导语:淘宝和导购平台互相纠缠,互相依赖成长共赢。导购平台会抢占淘宝的流量入口,淘宝需要导购平台的介入。本篇文章作者将复盘电商导购平台的沉浮史,其中的关键点,大家一起来看看吧! …
-
聚划算总经理(聚划算总经理 鬼谷)
据2021年6月鲸灵集团与见实联合发布的《私域电商崛起 2021私域流量白皮书》显示,2020年度小程序电商GMV为8000亿元,整体交易额同比去年增长了100%,人均交易金额提升…
-
南宋的都城(临安是不是南宋的都城)
为什么南宋皇帝要定都杭州,而不是南京? 首先,我们要搞清楚历代南朝建都南京,是为了方便向淮南投送兵力伺机北伐,而南宋都杭州,说明南宋连一丁点收复中原的勇气都没有。当然,定都南京倒不…
-
三星大屏幕手机(三星大屏幕手机8.2英寸)_2
11月29日,国内数码博主@i冰宇宙爆料称,三星Galaxy S22系列将于2月8日全球发布,2月18日正式开售,国行版发布和开售时间未知。 此外,@i冰宇宙还曝光了Galaxy …
-
淘宝 搜索(淘宝搜索发现怎么删除)
就连国民级别的绿色软件,都可以改微信号,为什么淘宝直到现在,还是“死不松口”呢? 其实,淘宝对于改名这事,已经做过回复。 嗯哼,这里千万别搞混了。 「淘宝昵称」和「淘宝会员名」是两…
-
腾飞论坛(飞腾帮论坛)
2022年1月3日,元旦假期最后一天,虽然冬日的气温较低,但仍然阻挡不了市民外出游玩。今日一早,家住成都市成华区的张先生带上一家四口,驱车前往青龙湖湿地公园,这个离家不远的湿地公园…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2000000@qq.com 举报,一经查实,本站将立刻删除。